
🎨 Three methods enclosed: Reck's, Clements', Yinyi's.
⭐️ An essential way to map deep neural networks onto unitary-based photonic AI circuits.
A methodology to bridge the transformation gap between the Euclidean operations in neural networks and the Hilbert operations in unitary-based photonic components.
💬 Preface
🎯 This post is of further elucidation affiliated to A Tutorial on Photonic Neural Networks, and serves to mathematically derive three decomposition methods that map matrix multiplications onto universal multiport interferometers. We also allude the theorems of matrix analysis. All the codes in this post are available on my github: Photonic-Neural-Networks.
🔑 The salient points of decomposition methods are as follows:
- How to apply appropriate mathematical factorization;
- How to map such mathematical conclusions onto the real physical devices.
🛫 Preliminaries
The decomposition methods listed above are component-independent. When changing the components such as from Mach Zehnder Interferometers (MZIs) to Microring Resonators (MRs), all we need is to substitute the basis that represents the targeted components before decomposing. To facilitate the comprehension, I use MZI as an example to extend the details of three decomposition methods.
🔮 Photonic Components
Let's start from the photonic components: coupler and phase shifter.
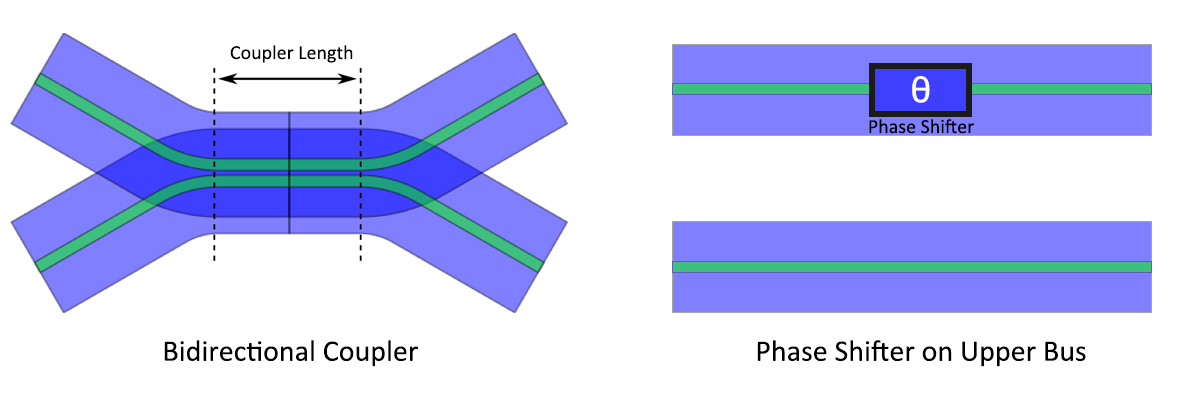
Running in a coherent manner, a coupler is defined as a transfer matrix of Equation 1, where is the effective coupling coefficients of the bidirectional waveguide, and denotes the coupling length. For a 3dB coupler, which indicates a 50:50 split ratio of light intensity, is devised as to meet the condition .
To make our photonic device programmable, we also need phase shifters. The phase difference incurs either constructive or destructive coherence of the light field. A phase shifter placed in the upper bus of two parallel interfere-less waveguide is defined in a matrix form, as shows in Equation 2. Phase is a reconfigurable variable that generalizes the alteration of refractive index (RI).
An MZI comprises two phase shifters and two 3dB couplers. Theoretically, two phase shifters are required to support complex matrix operations. Refer to my prior post:
Nevertheless, two phase parameters also deserve careful discussion. In fact, for a real-value matrix, is dispensable since itself can cover the unitary completeness. As we are towards quantum photonics, a matrix is not necessarily all real. Thus, is introduced to fulfill the domain of complex region. As opposed to the can be continuous in , the value of is discrete, which is one choice of .

Therefore, the unitary basis of MZI is as Equation 3. We also entitle it a 2-degree unitary block or a U(2) block. The imaginary part suggests the phase change induced by evanescent coupling from low-RI to high-RI medium.
The modeling scripts in Python is composed as follows. Again, you can find the complete codes on my github with comprehensive tutorial. The parameters dim, m, n denote the dimension or degree of the overall unitary matrix, m and n to impose U(2), respectively. and denote the passing loss and crossing loss respectively, which will be used in fidelity analysis.
import numpy as np
def U2MZI(dim, m, n, phi, theta, Lp=1, Lc=1):
assert m < n < dim
mat = np.eye(dim, dtype=np.complex128)
mat[m, m] = np.sqrt(Lp) * 1j * np.exp(1j * phi) * np.sin(theta)
mat[m, n] = np.sqrt(Lc) * 1j * np.cos(theta)
mat[n, m] = np.sqrt(Lc) * 1j * np.exp(1j * phi) * np.cos(theta)
mat[n, n] = -np.sqrt(Lp) * 1j * np.sin(theta)
return mat
🧲 Off-diagonal Nullification
Every unitary matrix is derived from the identity matrix with diagonal value of . We can use the arctan function to retrieve the angles that rotate, and to further determine the parameters and . An example is shown in Equation 4, given an arbitrary unitary matrix .
The math has claimed there always exists a value of basis in Equation 3 to nullify all the off-diagonal entries of the above matrix. We pick the left-bottom value together with the right-bottom value in Equation 4, and excute arctan to recover the angle.
# Aimed at MZI block
theta = np.pi/2 - np.arctan2( np.abs(U[0, 1]), np.abs(U[1, 1]) )
phi = np.angle( U[1, 1] ) - np.angle( U[0, 1] ) + np.pi
The hereby can be reverted to identity matrix (complex). The sequences of initial offsets are the angle of trace of the result matrix. In this manner, we successfully calculate the parameters and of a U(2).
>>> print( u @ U2MZI(dim=2, m=0, n=1, phi, theta) )
array([[0.-1.0j, 0.-0.0j],
[0.-0.0j, 0.-1.0j]])
Note that is one of the implementations of , which denotes a unitary transformation on and row. In the following sections, we will elucidate how to decompose a U(N) into pieces of U(2) blocks by three methods respectively.
🌠 Reck's Method
Reck's method was first proposed in 1994, demonstrating on the beam splitter platform [1]. As stated before, the decomposition methods are component-independent. It is thus compatible with the basis formed by MZI.

In a nut shell, Reck's method iteratively uses the property that the product is a unitary matrix which leaves all the columns in unaltered with the exception of columns and , and we can choose values for to nullify whatever entries in these columns [4].
Here we take nullifying U(4) in Equation 5 as an example. Similar to the off-diagonal nullification in the previous section, we choose a pair of for , of which values are determined by , to nullify the entries at the row and the column of matrix U, as shows in Equation 6.
Nextly we iterately nullify the entire row in a descend order by column index. Refer to the property of a unitary matrix that once a given row at the index are zero except then all the entries in the column are also zero, the rest of the matrix after nullification is shown in Equation 7. In other words, we start from the last row, and iterately nullify entries times in the row until all the off-diagonal entries are zero.
Let , Equation 7 is reformatted as . And the rest of the workflow is as Equation 8. Additional phase shifters are required. Their values are the angle of trace of the result matrix: .
For more details of the codes, please refer to my github. The APIs are listed below:
from pnn import decompose_reck, reconstruct_reck
[phi, theta, alpha] = decompose_reck(u, block='mzi')
u_r = reconstruct_reck(phi, theta, alpha, block='mzi')
🎆 Clements' Method
Clements' method is an optimized arrangement beyond Reck's, presented in 2016 [2]. It is based on an alternative arrangement of U(2) to reduce the footprint and improve the fidelity against the optical losses.
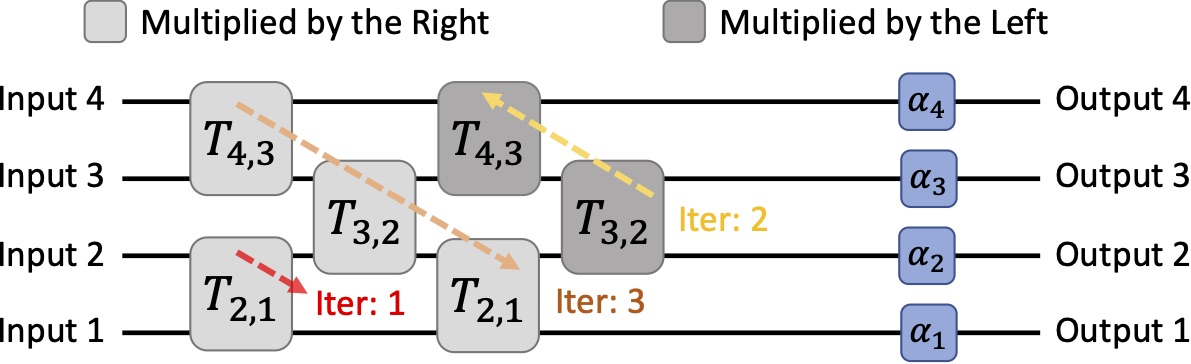
In contrast to Reck's method that successively multiply unitary matrices by the right to nullify the off-diagonal entries, Clements' method proceeds by nullifying successive diagonals of U(N) by alternating between and unitary matrices where [4]. To put it differently, and indicate the U(2) blocks from near-output and near-input, respectively. The star in blue color is the target to nullify, and the start in red is the value that aids in nullification. Specifically, the value is associated with .
Let's still use U(4) as the example. As opposed to Reck's, we start to nullify the entry at the left-bottom corner. Note that that multipies by the right indicates the nullification between and column, while that multiply by the left suggests the nullification between and row. The result is yielded in Equation 10.
To traverse the entries in a zig-zag manner, we gradually nullify the entries and make it a upper triangular matrix. For the odd iterations, we apply column nullification . For the even iterations, we apply row nullifications .
The result matrix is shown in Equation 12. The first iteration is . The second iteration comprises in order and . The third iteration comprises , and .
Note that the alternative form of is not friendly to the reconstruction. We are supposed to move all the transform unitary matrices to either left side or right side . Therefore, Equation 12 needs further reordering to yield the final form as Equation 13. is for reconstruction.
The derivation from to is demonstrated as Equation 14, where . To simplify the forms of the ensuing equations, we define .
Let , all the entries should match. By virtue of the properties of trigonometric functions, one of situations that meet the formula below are to suppress all the cosine and sine terms.
| Condition: |
|---|
The simplified results are shown in Equation 15 in the ensuing fashion. By moving to the right of consecutively, it yields as expects. contains the values of .
For more details of the codes, please refer to my github. The APIs are listed below:
from pnn import decompose_clements, reconstruct_clements
[phi, theta, alpha] = decompose_clements(u, block='mzi')
u_r = reconstruct_clements(phi, theta, alpha, block='mzi')
🎇 Yinyi's Method
I present a 3D-unfolding method to dramatically enhance computational density as we are towards miniaturization practice of photonic neural networks for Internet of Thing [3].
🚴 Motivation
Integrated photonic neural networks, which are based on universal multiport interferometers (UMI), have already evolved from hype to reality over past few years. A fairly solid foundation of working mechanism, continuing progress ranging from fabrication maturities to algorithm advances push universal multiport interferometers forward. Some startup commanies have aggressively taped out wafer-scale photonic chips for datacenters.
Despite the great potentials mentioned above, such photonic paradigms have not yet delivered on the promises in miniaturization practice. In general, the footprints of photonic components are several orders of magnitudes larger than those of electronic devices. For instance, the length of an arm in MZI is over hundreds of micrometers. A planar arrangement, by either Reck's or Clements', to support matrix multiplications on multiport interferometers will occupy a whole 4-inch wafer. The horribly large size impedes the integration of such photonic neural networks into mobile devices and other agile apparatuses, which literally extinguishes the prospects for AI in Internet of Thing with Photonics.
It is therefore imperative to reduce the footprints and improve the computational density. Remind that Reck's and Clements' are both planar decomposition, will it be possible to explore the optimal 3D arrangement for unitary blocks? The answer is YES. Here we propose a novel 3D-unfolding method based on cosine-sine decomposition (CSD).
💡 Methodology
As a starting point, we mathematically investigate the properties of CSD. We begin with a weight matrix obtained from the layer of a deep neural network model. Typically, the weight matrix is mapped to unitary domain via Singular Value Decomposition (SVD), that is . It yields two orthogonal matrices and . For simplicity, we use M to represent either U or V as the input matrix at a single execution of our unfolding method. Each unitary matrix is partitioned into four sub-matrices with the size of , , and . Here and its remainders straightforward determine the planar scales of UMI at each layer. Since the overall footprints are subject to the largest area among layers, the value of should be as close to that of as possible to make balance unfolding. Empirically, when is even, and when is odd.
For the next step, we apply CSD to with balanced parameters of as stated. There exists orthogonal matrices , and diagonal matrices comprosed of trigonometric , . The entire formula is as follows:

denotes an identity matrix, and holds for any corresponding entries of and . For each pair of and , they indicate a vertical coupling block. By contrast, and are the planar or horizontal coupling in a way like Reck's or Clements'. It suggests our method is fully compatible with two canonical methods, while further enabling the arrangement along the direction that is perpendicular to the plane.
The illustration of the CSD-based unfolding method for a UMI is depicted below. We get down to Clements' planar decomposition method a a baseline in sub-figure (a). It represents a unitary matrix . Before CS-decomposition, is evenly partitioned into four sub-matrix blocks in green color shown in sub-figure (b). Note that the colors of matrices correspond to the waveguide mesh colors in the subfigure (c) and (d). To reconstruct each layer PNNs from the unfolding sub-matrices, the and correspond to the planar waveguide mesh. The black arrow-lines suggest that inter-layer and share resemble ports and structures, which can be amalgamated along the vertical direction. We hereby complete a single execution of CSD.
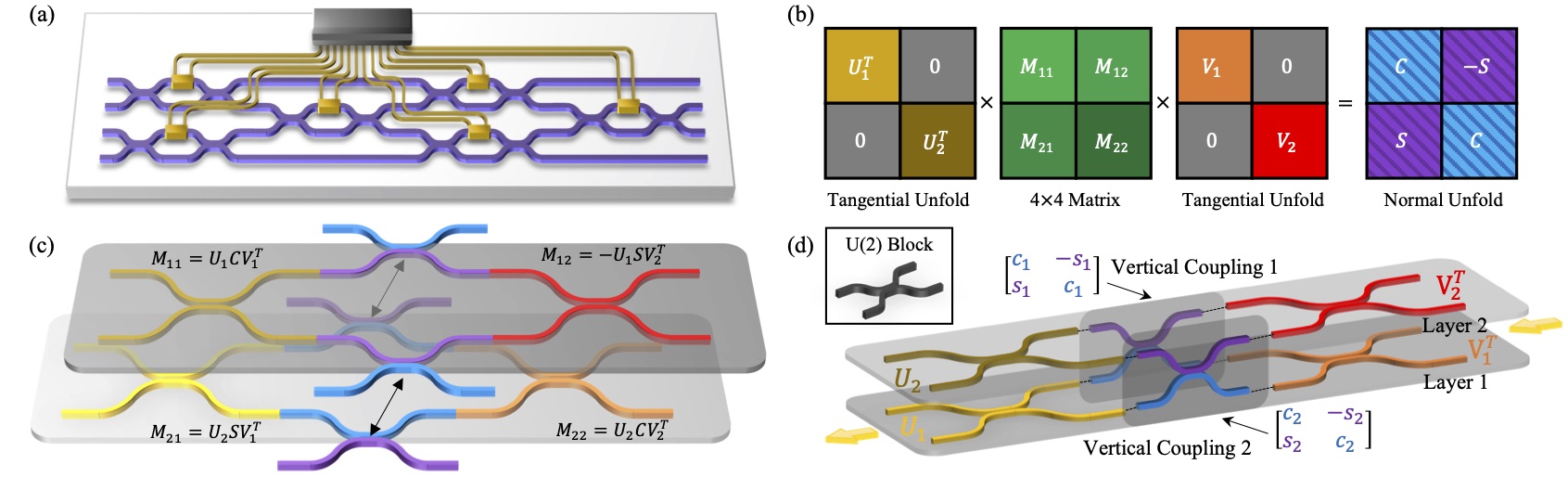
Since the sub-matrices and still maintain the consistency of unitary properties, our CSD method can iteratively apply to the rest of the sub-matrices and achieve multi-layer stacking along the plane normal. In addition, the method is highly customizable in terms of the vertical stacking number. From the perspective of the algorithm, that each unitary matrix is decomposed into two sub-matrices is associated with the binary tree. By specifying the tree depth, the numbers of vertical layers are determined.
For more details of the codes, please refer to my github. The APIs are listed below:
class UmiCsd:
def decompose(matrix, p=None, q=None) -> None
def decompose_recursive(depth) -> None
def reconstruct(Lp_dB=0, Lc_dB=0, method='clements', block='bs') -> numpy.ndarray
The method in UmiCsd.reconstruct() denotes the planar decomposition method, including Reck or Clements. In summary, our proposed CSD method is compatible with Reck's and Clements' method, while ours enables spatial arrangement along new axis to reduce the footprint areas.
🗯 Discussion
FAQ: Why not simply stacking each planar layers without vertical coupling? The fabrication process seems more viable.
It is important to recognize the defects of photonic systems before we move on. A commonsense is that buffering or storage is extremely expensive in the photonic system due to the intrinsic properties of photons. Moreover, to pursue ultra-low power consumption, the devised system is supposed to avoid frequent optical-to-electrical (OE) conversions and vice versa.
And let's back to the question. The arithmetic operations behind stacking each planar layers without vertical coupling actually, which are in essence tiled multiplications, are NOT equivalent to those of our method. Simply stacking calculates each sub-matrice as tiles individually, and the results of output ports between layers are mutually independent. To acquire the final results, we still need extra components of either photonic buffers or intra-mesh OE conversions to store, synchronize and accumulate the partial sum produced from tiles. As stated in the last paragraph, these devices are not impractical for photonic systems.
Futhermore, even if we argument simply stacking by attaching vertical coupling to avoid buffering and intra-mesh OE conversions, our CSD is the optimal design with respect to both the fidelity and footprints.
🧐 Comparison
📐 Fidelity
🔩 Footprint
📝 Conclusion
📖 References
[1] Reck, Michael, et al. "Experimental realization of any discrete unitary operator." Physical review letters 73.1 (1994): 58.
[2] Clements, William R., et al. "Optimal design for universal multiport interferometers." Optica 3.12 (2016): 1460-1465.
[3] Liu, Yinyi, et al. "Reduce footprints of multiport interferometers by cosine-sine-decomposition unfolding." Optical Fiber Communication Conference and Exhibition (2022): W2A.4.
[4] Pérez, Daniel, et al. "Principles, fundamentals, and applications of programmable integrated photonics." Advances in Optics and Photonics 12.3 (2020): 709-786.